Data enrichment use-case with DMN and BPMN
21 January 2022
In this post I want to share an interesting use case of data enrichment, using DMN with BPMN and other open standards.
The typical usage pattern for data enrichment is the following: a complex data structure containing several attributes is provided as input; based on some computations and decision results, the original structure is enriched with additional attributes. In an even more complex scenario, already existing specific attributes are overridden with new values.
Often this usage pattern is referred to as “mutability”, but speaking about mutability is an improper terminology to be used in the context of DMN; DMN is stateless and mandates that “all decision logic is free of side-effects” (DMN Specification chapter 5.2.3) among other idempotent and deterministic requirements.
Instead a more important aspect to focus on, while considering this use-case, is that Functional Programming has taught us powerful lessons which can be applied in this context: we can achieve the desired goal by pushing side-effects at the boundaries, or by adopting other FP strategies.
In this post we will see how we don’t strictly need mutability features, in order to effectively achieve data enrichment.
I will demonstrate the pragmatic implementation of this use-case, both by using DMN as a standalone knowledge asset, as well as combining the same DMN model with a BPMN process.
Introduction
For the remainder of this post, we will use a running example where the fundamental Domain Model is a structure dealing with an incoming request of Tech Support.
This can be represented as a DMN ItemDefinition, shown in the screenshot below; we can also use the idiomatic Java Pojo representation, following the Kie v7 conventions:

For this example, we can notice most attributes are pertaining to the event of the support request being raised:
"Support Request" : {
"full name" : "John Doe",
"email" : "info@redhat.com",
"mobile" : "+1",
"mailing address" : "somewhere",
"account" : "47",
"premium" : false,
"area" : "tech",
"description" : "app crashed"
}all except for the priority attribute.
The goal of the business application is to process the support request, establish the appropriate priority level, and then produce a support request with the priority attribute now correctly valorized.
While looking in details at this example, I will keep the decision logic simple and we will not use any complex decision logic to actually determine the priority value; as mentioned, the focus of this post is the processing of the incoming payload, to produce a fully valorized support request, also including the actual priority value.
Strategy A: combine DMN with BPMN
A first approach is to combine DMN and BPMN for the best of both worlds: DMN should focus on the decision logic keeping an immutable and stateless approach, while BPMN is used to manage in a stateful manner the different stages of processing for the support request.
The DMN model can focus on the decision logic to establish the appropriate Priority value, depending on the content of the incoming support request:

The current decision logic in the example right now is quite simplistic because as mentioned is not the most important aspect, but naturally can be further extended to have a more complex decision table, etc:

Now we need to have as output almost the ~same structure we have received as input, and override it with the combination of the key-value pair for Priority, having value either “High” or “Medium”.
We can use for this goal a BPMN process:
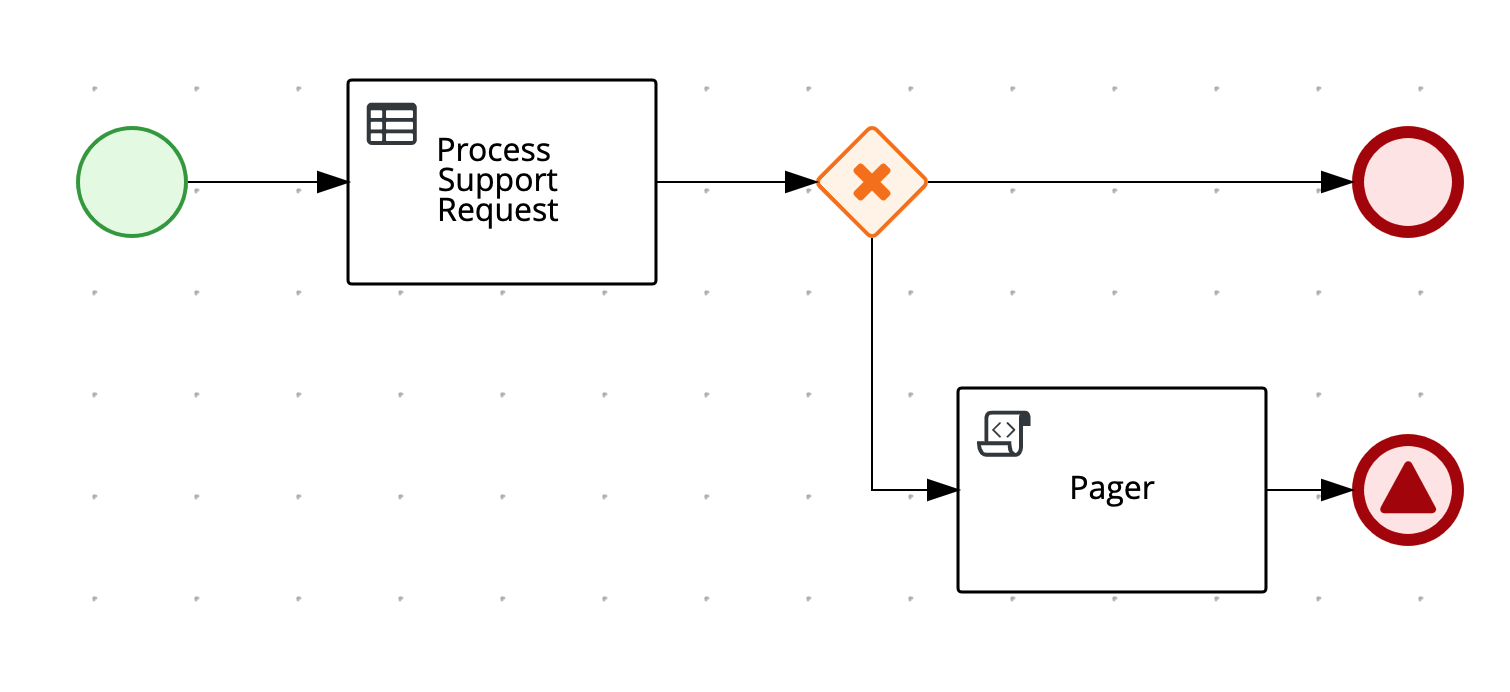
The process is started by receiving as input the support request payload, stored as a process variable named “request”.
The first BPMN Task, named “Process Support Request”, is in charge of:
- Invoke the evaluation of the DMN model, passing the incoming support request (the “request” process variable) as input of the DMN evaluation.
- Take the output decision of the DMN evaluation, “Determine Priority”, and assign it to a temporary process variable called “priority”.
- Modify the “request” process variable, with the value now contained in the “priority” from step2.
You can find more details about these three steps of the “Process Support Request” Task in the next section.
Later, the “request” process variable is will be fully valorized as well in the priority attribute, so that can be used in the gateway, as one would naturally expect:
This has achieved the original requirements.
Details
The final step 3 of the “Process Support Request” BPMN Task in effect mutates the original structure; however, it is important to be noted that the mutation happens indeed in the context of a BPMN process, which naturally allows for statefulness, mutations, side-effects, etc.
In this strategy, we have kept the DMN model fully focused on the actual decision, that is the determination of the priority for the given support request.
Currently this is implemented on jBPM Kie v7 with the three steps described above, meaning it can be achieved already today by:
Input “Support Request” <- request (process variable)
Output “Determine Priority” -> priority (process variable)
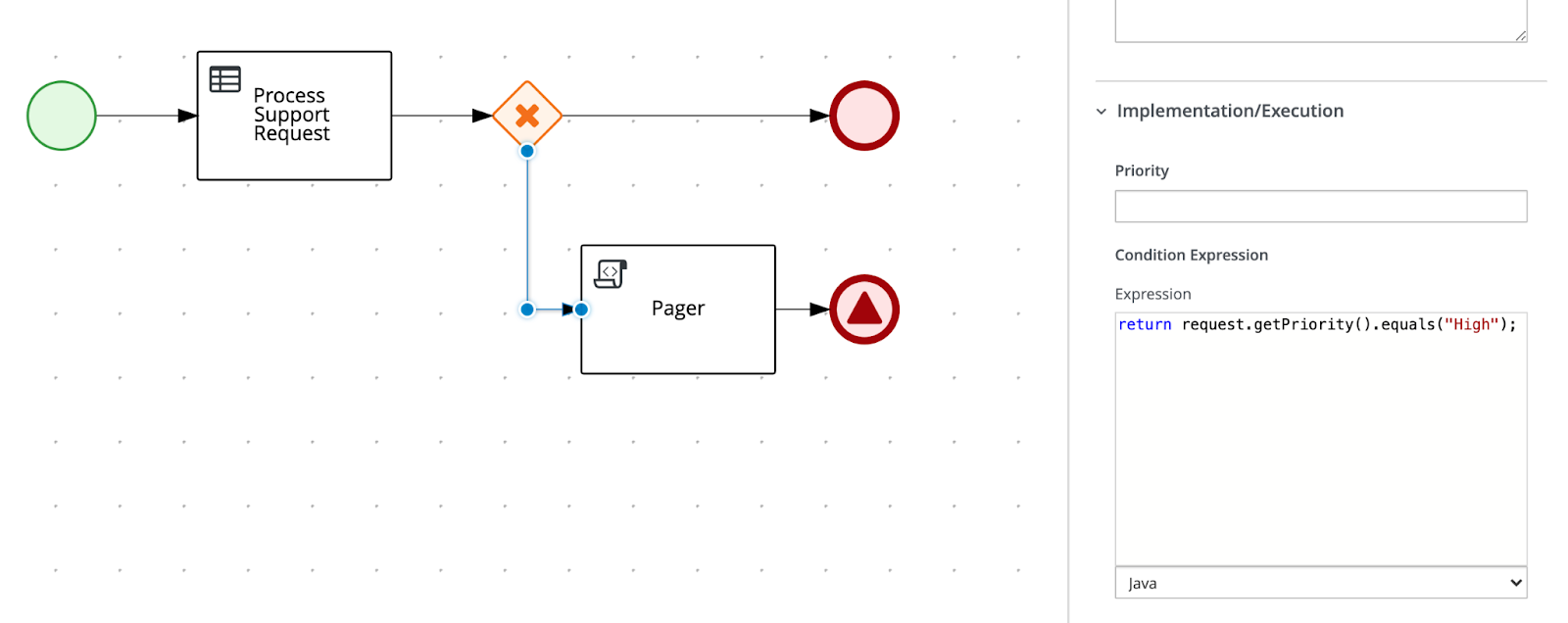
Please notice in the screenshot both the assignment in the foreground to a temporary process variable name “priority” (step2) and in the background the modification of the support request in the attribute “priority” using the On Exit Action script (step3).
Step2 and Step3 of the “Process Support Request” Task, in the future, could be combined in the Data Assignment, directly in the Task’s “Data I/O”, when support for expressions will be fully implemented.
Something that could potentially look like this:
Input “Support Request” <- request (process variable)
Output “Determine Priority” -> ${request.priority} (expression)Support for expressions is currently being discussed for FEEL in future iterations and might achieve something similar.
Strategy B: using DMN standalone
Another approach is to use DMN only; in this case we cannot modify the original InputData value, but we can definitely create an exact copy of the input payload structure but altered only on the desired attribute “priority”.
Naturally we want to do this without having to replicate manually all the original attributes, which would be extremely tedious!
NOTE: this approach is still fully compliant with the DMN Specification semantics, meaning free of side-effects and stateless.
We introduce a new built-in function called “context put”: this function takes 3 parameters:
- “context” of type context (a composite structure in DMN terms)
- “key” of type string
- “value” of Any type
and produces a resulting context altered in the key-value pair, or enriched of the new key-value pair.
For example:
context put({ name: "John Doe" }, "age", 47)would result in:
{ name: "John Doe", age: 47 }You might have some ideas by now about where this is about to go :)
We can achieve something similar to:
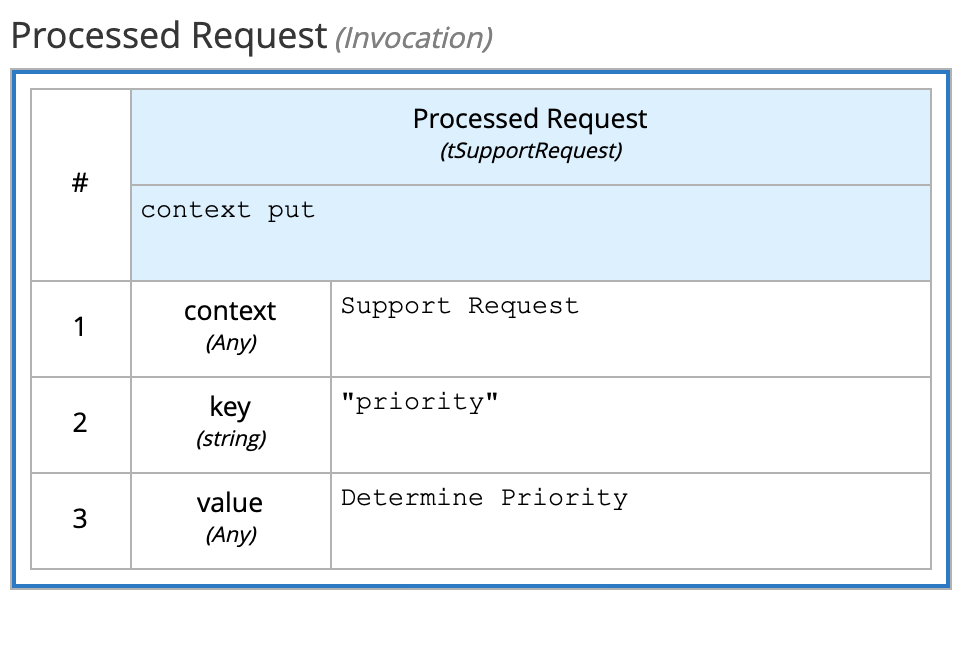
context put( <request> , "priority", ... )This in fact it is pretty easy, by taking the previous DMN model and adding just one more Decision to keep the clarity of the decision logics in the DRG:

In this DRD picture I’ve used the same colour to highlight both nodes “Support Request” and “Processed Request” having the same typeRef, meaning both nodes conform to the ItemDefinition “tSupportRequest” originally shown at the beginning of this post.
The decision logic for “Processed Request” is super simple, meaning:

As we have learnt, that means: produce the same structure of the node “Support Request” but altered (or appended) with a new key-value pair, having key “priority” and having value from the “Determine Priority” sub-decision.
So we have achieved the same goal, following another strategy now; we have as output Decision the same structure we see in one of the InputData, but valorized in the new “priority” attribute value!
This would also work in a totally equivalent BPMN process too:

This BPMN process is now simpler in the Task's Data I/O Assignments, as we no longer need the previously required Step2+Step3.
The BPMN "Process Support Request" Task now simply uses:
Input “Support Request” <- request (process variable)
Output “Processed Request” -> request (process variable)
This works perfectly thanks to the awesome contributions by Anton Giertli clarifying requirements and work by Enrique Gonzalez Martinez with JBPM-9783, allowing a better integration of the DMN results with the jBPM’s BRE Task!
Details
Adopting the same JSON originally presented at the beginning of this post, we can use that as a DMN input payload and check the results using this DMN model alone.
DMNContext of INPUT:
{
"Support Request" : {
"account" : "47",
"email" : "info@redhat.com",
"mobile" : "+1",
"premium" : false,
"area" : "tech",
"description" : "app crashed",
"priority" : null,
"full name" : "John Doe",
"mailing address" : "somewhere"
}
}DMNResult of OUTPUT:
{
"Support Request" : {
"account" : "47",
"email" : "info@redhat.com",
"mobile" : "+1",
"premium" : false,
"area" : "tech",
"description" : "app crashed",
"priority" : null,
"full name" : "John Doe",
"mailing address" : "somewhere"
},
"Determine Priority" : "Medium",
"Processed Request" : {
"area" : "tech",
"premium" : false,
"mobile" : "+1",
"description" : "app crashed",
"mailing address" : "somewhere",
"full name" : "John Doe",
"priority" : "Medium",
"account" : "47",
"email" : "info@redhat.com"
}
}This "context put" function is not part of the DMN v1.3 specification, so at the time of writing this is to be considered an experimental and extended built-in function, even if it is actually provided as part of the Drools DMN Engine out of the box. The DMN Revision Task Force group might decide to eventually adopt this in a future release of the specification. In fact, this blog post takes inspiration from drawing additional consequences after a Vendor proposal raised similar use-case in the DMN RTF Group: I believe this is a very encouraging demonstration of the power of open standards and their communities, where innovations are generated by the collaboration of different Vendors! Previously, we have been internally experimenting with a similar concept called “lambda-update(object,[fields])”, but the ultimate approach presented with this post is much simpler.
In the meantime of that final DMN approval, the usage of this extended built-in function is to be considered experimental.
The DMNContext in the dmn output results contains as expected the two structures, and they both conform to the ItemDefinition defining the content of said structure, as expected. On the Drools DMN Engine Java API however as we have learnt, they are not the same instances and they are not necessarily the same Java class: it could be the case the input is supplied as a Pojo and the output resulting as a java.util.Map, or it could also work by having a java.util.Map as input and again as output. Naturally in any case, either the Pojo or either the java.util.Map must conform (or do conform automatically when produced by the engine) to the applicable ItemDefinition(s), meaning they include all the properties expected from the ItemDefinition’s components. This is an implementation detail of the embedded Java API, and it is completely transparent when dealing with REST APIs, such as those code generated on a Kogito based application, or by leveraging the Kie Server’s “Next generation DMN model specific endpoints” (BAPL-1787). This is also completely transparent when integrating DMN inside a jBPM BRE Task, as mentioned thanks to the improvement of (JBPM-9783).
The same decision logic for the new Decision node could have equivalently be expressed with a boxed function invocation too:
The same DMN model would indeed code generate the expected REST API endpoint definitions on a Kogito based application too:

We can notice the payload structure both in Request and Response of the Swagger / OpenAPI is the expected one.
What about data transformation?
This example naturally draws even closer to additional use-cases which can be integrated in the context of DMN implementation, such as data transformation.
The power of DMN can be fully exploited when using its notation to describe business rules and decision logic, and while it can be also employed to “transform” data in a way similarly described in this post, using DMN purely for data transformation may not always be the best solution. For the use-case dealing only with pure data transformation requirements, we suggest you also take a look at AtlasMap, a data mapping solution with interactive web based user interface.
Conclusions
We have learnt how to leverage open standards in the best possible way to achieve the desired goals, even better by considering two very pragmatic strategies:
- Combine DMN with the power of BPMN
- Use DMN standalone and an extended feature
We have also seen how integrations and collaborations are foundational elements which allowed us to achieve these important results!
Demo code material is available, which can be used as reference for the content presented in this post, at: https://github.com/tarilabs/dmn-data-enrichment-20210804
What do you think of these approaches? Let us know in the comments down below!